최근 들어 SNS 등으로 특정 인물의 얼굴을 고정시켜 줄 수 있겠냐는 문의가 들어와서 한번 도전해 보았습니다. 그 실행기를 공유해 봅니다. 잘 따라오시면 성공할 확률이 높을 것이라 생각이 됩니다. 이 포스팅은 아카라이브 채널과 깃허브, 허깅페이스에서 관련 정보를 찾아서 제가 시행착오를 겪은 내용을 바탕으로 가공하였으니 참고해 주세요. 관련 정보 링크는 포스팅 내 별도 공유하겠습니다. 그럼 시작~!
1. 기본 준비 사항
- NVIDIA 그래픽카드 VRAM 6GB 이상 권장
- python 3.10.x : 이미 stable diffusion webui (이하 SD)를 사용하고 있다면 별도로 설치할 필요는 없습니다.
- 학습시킬 데이터셋
: 저의 경우 얼굴을 학습시키고 싶어 얼굴이 잘 나온 이미지로 35장 준비했습니다. 크기는 512 x 512 이상이 좋음.
- kohya_ss : kohya_ss 드림부스 기반 LoRA GUI라고 합니다. 이 외에도 LoRA 학습 방법이 있습니다. (ex :sd-webui-additional-networks) 저는 kohya_ss로 설치했습니다
- WD Tagger 1.4 : 학습시키기 위해 모아 놓은 이미지에 프롬프트 태그를 추출해주기 위한 SD 확장입니다.
2. PowerShell 정책 해제 및 설치 폴더 생성
윈도우에서 파워쉘을 검색하여 관리자로 실행합니다.

1) Set-ExecutionPolicy Unrestricted 입력 후 A를 입력
2) Get-ExecutionPolicy 입력 후 Unrestricted로 출력되는지 확인을 해줍니다.
3) 파워쉘 종료

4) kohya_ss를 설치할 폴더를 생성하고 그곳에서 shift+오른 클릭으로 파워쉘을 실행합니다.

3. kohya_ss 설치
파워쉘에서 "git clone https://github.com/bmaltais/kohya_ss.git "을 입력해서 설치를 합니다.

setup.bat을 실행하면 설치가 진행되는데요. recommanded 써져 있는 것으로 선택을 해줍니다.

설치가 어느 정도 진행되다 보면 아래와 같은 화면이 나옵니다.

* This machine : 엔터를 눌러줍니다.
* No distributed training : 엔터를 눌러줍니다.
Do you want to run your training on CPU only (even if a GPU / Apple Silicon device is available)? [yes/NO]: 엔터를 눌러줍니다.
Do you wish to optimize your script with torch dynamo?[yes/NO]:엔터를 눌러줍니다.
Do you want to use DeepSpeed? [yes/NO]: 엔터를 눌러줍니다.
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]: all을 입력 후 엔터
Do you wish to use FP16 or BF16 (mixed precision)? 1을 입력후 엔터 (fp16을 선택)
여기까지 하시면 파워쉘이 자동종료가 되면서 설치는 완료가 됩니다.
4. kohya_ss 실행
설치된 폴더 안에 gui.bat을 실행시키면 SD를 실행할 때 와 마찬가지로 local URL 주소를 알려줘서 실행시키는 화면이 나옵니다.

5. 학습할 그림자료에 태깅하기
별도의 폴더를 생성해서 학습할 이미지를 넣어둡니다. 이미지는 512 x 512 이상으로 사이즈를 조절해 둡시다. 저는 c:\img에 넣어두었습니다. 그리고 SD를 실행해서 WD Tagger 1.4를 설치해 주세요. SD > Extensions > Install from URL > https://github.com/toriato/stable-diffusion-webui-wd14-tagger 입력 후 인스톨을 하고 SD를 껐다가 다시 실행해 줍니다.

wd 14 tagger는 이미지에 프롬프트 태그를 생성해 주는 Extensions입니다. 학습할 때 프롬프트 태그를 인식해야 하므로 이 단계가 필요합니다. 다른 태깅 앱을 사용해도 상관없을 것으로 생각됩니다.
SD 화면에서 Tagger > Batch from directory로 들어와서 Input directory에 모아놓은 이미지의 위치를 넣어줍니다.
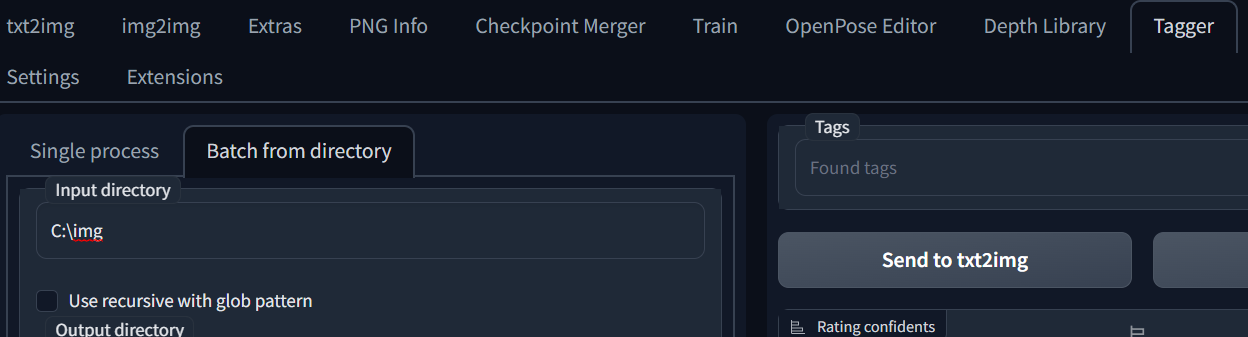

위와 같이 옵션을 체크해 주시고 ' Interrogate ' 실행해 주면 이미지를 모아놓은 폴더에 자동으로 태그파일이 생성된 것을 볼 수 있습니다.

여기서 SD의 역할은 끝났으니 종료합니다.
6. kohya_ss 세팅하기
세팅은 컴퓨터 환경에 따라 설정이 바뀔 수 있으니 참고만 하시고 본인 PC에 맞는 옵션을 찾아가시길 바랍니다. 저의 경우 아래와 같이 세팅해서 실행에 성공했습니다.
1) Dreambooth LoRa > Source model 세팅 화면

* v2는 SD 2.x 모델을 사용하는 경우에만 체크합니다.
2) Dreambooth LoRa > Tools > Dreambooth/LoRa Folder preparation
- instance prompt : 1 토큰을 입력하는 곳으로 아래 깃허브 링크를 참고해서 넣어주시면 됩니다.
https://github.com/2kpr/dreambooth-tokens/blob/main/all_single_tokens_to_4_characters.txt
- Class prompt : 어떤 스타일을 학습시킬지 입력하는 곳입니다. ex) girl, boy, style, fashion, art 등
- Trainning images : 앞서 만들어놓은 데이타셋의 위치입니다. (학습할 이미지와 태그.txt 파일이 있는 곳)
- Repeats : 얼마나 반복학습 시킬지 입력하는 곳입니다.
- Regularisation images : 정규화 이미지 폴더를 지정합니다. (학습시킬 모델에서 정규화 이미지를 1000장 정도 뽑아 놓으면 더 정확한 로라 구현이 가능하다고 하는데 저는 아직 안 해봤습니다.)
- Destination training directory : 학습시킬 결과물이 들어가게 될 폴더입니다.

- Prepare training data : 위의 세팅 후에는 꼭! 눌러주시기를 바랍니다. 누르고 CMD창에서 제대로 실행되었는지 확인해 보세요.
3) Dreambooth LoRa > Folders
- image, output, logging folder : 위에서 정상적으로 Prepare training data를 진행해서 생성된 폴더 경로를 넣어줍니다
- Model output name : 생성될 LoRa의 이름을 정해줍니다.

4) Dreambooth LoRa > Training parameters
옵션이 너무 많아서 뭘 설정해야 될지 감이 안 옵니다. 지금부터 천천히 공부해 보시면서 옵션을 하나씩 적용해 보시길 바랍니다. 아래는 웹 검색하여 참고한 내용을 바탕으로 성공한 일반적인 세팅 환경입니다.

5) Dreambooth LoRa > Training parameters > Advanced Configuration

7. Train model
세팅이 완료되면 Train model을 눌러주세요.
정상적으로 세팅이 되었다면 CMD 창에서 학습이 진행되는 화면을 볼 수 있습니다.

8. 설치 및 실행문제 참고하기
저도 3일에 걸쳐 몇 번의 시행착오를 경험하고 힘들게 해결했는데요. 깃허브 링크의 이슈해결 내용을 참고해 문제를 하나씩 줄여나가다 보면 최종 실행이 가능할 것입니다!!
또는 댓글로 문의하시면 부족하지만 도움드릴 수 있도록 같이 고민하겠습니다!
관련 최신 글 :
2024.11.08 - [[TIP] Stable Diffusion] - CivitAI로 나만의 LoRA 모델 만드는 방법: 단계별 가이드와 팁
CivitAI로 나만의 LoRA 모델 만드는 방법: 단계별 가이드와 팁
혹시 자신만의 AI 모델을 만들어보고 싶은데, 어디서부터 시작해야 할지 막막하신가요? 또는 특정 스타일의 그림을 AI에게 학습시키고 싶지만 복잡한 프로그래밍 과정이 두렵다면, 이번 포스트
doobam.zumi100.com
'[TIP] Stable Diffusion' 카테고리의 다른 글
| [SD. TIP] 컨트롤넷(controlnet) 1.1 업스케일, tile_resample (0) | 2023.05.25 |
|---|---|
| 동영상 보간 작업 쉽게하기, Flowframes 설치 및 사용법 (0) | 2023.05.18 |
| stable diffusion : vladmandic 버전 (0) | 2023.04.29 |
| [SD. TIP] controlnet으로 원하는 포즈를 추출하자 (0) | 2023.04.07 |
| [SD. TIP] Photoshop에서 SD를 사용하자! (1) | 2023.03.23 |




댓글